|
11/1/2021 0 Comments Get Quality Preparation with SAS Statistical Business Analyst (A00-240) CertificationSAS Statistical Business Analyst certification questions and exam summary helps you to get focused on the exam. This guide also helps you to be on A00-240 exam track to get certified with good score in the final exam.  SAS Statistical Business Analyst (A00-240) Certification Summary
SAS Statistical Business Analyst (A00-240) Certification Exam Syllabus 01. ANOVA - 10% Verify the assumptions of ANOVA - Explain the central limit theorem and when it must be applied - Examine the distribution of continuous variables (histogram, box -whisker, Q-Q plots) - Describe the effect of skewness on the normal distribution - Define H0, H1, Type I/II error, statistical power, p-value - Describe the effect of sample size on p-value and power - Interpret the results of hypothesis testing - Interpret histograms and normal probability charts - Draw conclusions about your data from histogram, box-whisker, and Q-Q plots - Identify the kinds of problems may be present in the data: (biased sample, outliers, extreme values) - For a given experiment, verify that the observations are independent - For a given experiment, verify the errors are normally distributed - Use the UNIVARIATE procedure to examine residuals - For a given experiment, verify all groups have equal response variance - Use the HOVTEST option of MEANS statement in PROC GLM to asses response variance Analyze differences between population means using the GLM and TTEST procedures - Use the GLM Procedure to perform ANOVA CLASS statement MODEL statement MEANS statement OUTPUT statement - Evaluate the null hypothesis using the output of the GLM procedure - Interpret the statistical output of the GLM procedure (variance derived from MSE, F value, p-value R**2, Levene's test) - Interpret the graphical output of the GLM procedure - Use the TTEST Procedure to compare means Perform ANOVA post hoc test to evaluate treatment effect - Use the LSMEANS statement in the GLM or PLM procedure to perform pairwise comparisons - Use PDIFF option of LSMEANS statement - Use ADJUST option of the LSMEANS statement (TUKEY and DUNNETT) - Interpret diffograms to evaluate pairwise comparisons - Interpret control plots to evaluate pairwise comparisons - Compare/Contrast use of pairwise T-Tests, Tukey and Dunnett comparison methods Detect and analyze interactions between factors - Use the GLM procedure to produce reports that will help determine the significance of the interaction between factors. MODEL statement - LSMEANS with SLICE=option (Also using PROC PLM) - ODS SELECT - Interpret the output of the GLM procedure to identify interaction between factors: - p-value - F Value - R Squared - TYPE I SS - TYPE III SS 02. Linear Regression - 20% Fit a multiple linear regression model using the REG and GLM procedures - Use the REG procedure to fit a multiple linear regression model - Use the GLM procedure to fit a multiple linear regression model Analyze the output of the REG, PLM, and GLM procedures for multiple linear regression models - Interpret REG or GLM procedure output for a multiple linear regression model: convert models to algebraic expressions - Convert models to algebraic expressions - Identify missing degrees of freedom - Identify variance due to model/error, and total variance - Calculate a missing F value - Identify variable with largest impact to model - For output from two models, identify which model is better - Identify how much of the variation in the dependent variable is explained by the model - Conclusions that can be drawn from REG, GLM, or PLM output: (about H0, model quality, graphics) Use the REG or GLMSELECT procedure to perform model selection - Use the SELECTION option of the model statement in the GLMSELECT procedure - Compare the differentmodel selection methods (STEPWISE, FORWARD, BACKWARD) - Enable ODS graphics to display graphs from the REG or GLMSELECT procedure - Identify best models by examining the graphical output (fit criterion from the REG or GLMSELECT procedure) - Assign names to models in the REG procedure (multiple model statements) Assess the validity of a given regression model through the use of diagnostic and residual analysis - Explain the assumptions for linear regression - From a set of residuals plots, asses which assumption about the error terms has been violated - Use REG procedure MODEL statement options to identify influential observations (Student Residuals, Cook's D, DFFITS, DFBETAS) - Explain options for handling influential observations - Identify collinearity problems by examining REG procedure output - Use MODEL statement options to diagnose collinearity problems (VIF, COLLIN, COLLINOINT) 03. Logistic Regression - 25% Perform logistic regression with the LOGISTIC procedure - Identify experiments that require analysis via logistic regression - Identify logistic regression assumptions - logistic regression concepts (log odds, logit transformation, sigmoidal relationship between p and X) - Use the LOGISTIC procedure to fit a binary logistic regression model (MODEL and CLASS statements) Optimize model performance through input selection - Use the LOGISTIC procedure to fit a multiple logistic regression model - LOGISTIC procedure SELECTION=SCORE option - Perform Model Selection (STEPWISE, FORWARD, BACKWARD) within the LOGISTIC procedure Interpret the output of the LOGISTIC procedure - Interpret the output from the LOGISTIC procedure for binary logistic regression models: Model Convergence section - Testing Global Null Hypothesis table - Type 3 Analysis of Effects table - Analysis of Maximum Likelihood Estimates table - Association of Predicted Probabilities and Observed Responses Score new data sets using the LOGISTIC and PLM procedures - Use the SCORE statement in the PLM procedure to score new cases - Use the CODE statement in PROC LOGISTIC to score new data - Describe when you would use the SCORE statement vs the CODE statement in PROC LOGISTIC - Use the INMODEL/OUTMODEL options in PROC LOGISTIC - Explain how to score new data when you have developed a model from a biased sample 04. Prepare Inputs for Predictive Model Performance - 20% Identify the potential challenges when preparing input data for a model - Identify problems that missing values can cause in creating predictive models and scoring new data sets - Identify limitations of Complete Case Analysis - Explain problems caused by categorical variables with numerous levels - Discuss the problem of redundant variables - Discuss the problem of irrelevant and redundant variables - Discuss the non-linearities and the problems they create in predictive models - Discuss outliers and the problems they create in predictive models - Describe quasi-complete separation - Discuss the effect of interactions - Determine when it is necessary to oversample data Use the DATA step to manipulate data with loops, arrays, conditional statements and functions - Use ARRAYs to create missing indicators - Use ARRAYS, LOOP, IF, and explicit OUTPUT statements Improve the predictive power of categorical inputs - Reduce the number of levels of a categorical variable - Explain thresholding - Explain Greenacre's method - Cluster the levels of a categorical variable via Greenacre's method using the CLUSTER procedure METHOD=WARD option FREQ, VAR, ID statement Use of ODS output to create an output data set - Convert categorical variables to continuous using smooth weight of evidence Screen variables for irrelevance and non-linear association using the CORR procedure - Explain how Hoeffding's D and Spearman statistics can be used to find irrelevant variables and non-linear associations - Produce Spearman and Hoeffding's D statistic using the CORR procedure (VAR, WITH statement) - Interpret a scatter plot of Hoeffding's D and Spearman statistic to identify irrelevant variables and non-linear associations Screen variables for non-linearity using empirical logit plots - Use the RANK procedure to bin continuous input variables (GROUPS=, OUT= option; VAR, RANK statements) - Interpret RANK procedure output - Use the MEANS procedure to calculate the sum and means for the target cases and total events (NWAY option; CLASS, VAR, OUTPUT statements) - Create empirical logit plots with the SGPLOT procedure - Interpret empirical logit plots 05. Measure Model Performance - 25% Apply the principles of honest assessment to model performance measurement - Explain techniques to honestly assess classifier performance - Explain overfitting - Explain differences between validation and test data - Identify the impact of performing data preparation before data is split Assess classifier performance using the confusion matrix - Explain the confusion matrix - Define: Accuracy, Error Rate, Sensitivity, Specificity, PV+, PV- - Explain the effect of oversampling on the confusion matrix - Adjust the confusion matrix for oversampling Model selection and validation using training and validation data - Divide data into training and validation data sets using the SURVEYSELECT procedure - Discuss the subset selection methods available in PROC LOGISTIC - Discuss methods to determine interactions (forward selection, with bar and @ notation) - Create interaction plot with the results from PROC LOGISTIC - Select the model with fit statistics (BIC, AIC, KS, Brier score) Create and interpret graphs (ROC, lift, and gains charts) for model comparison and selection - Explain and interpret charts (ROC, Lift, Gains) - Create a ROC curve (OUTROC option of the SCORE statement in the LOGISTIC procedure) - Use the ROC and ROCCONTRAST statements to create an overlay plot of ROC curves for two or more models - Explain the concept of depth as it relates to the gains chart Establish effective decision cut-off values for scoring - Illustrate a decision rule that maximizes the expected profit - Explain the profit matrix and how to use it to estimate the profit per scored customer - Calculate decision cutoffs using Bayes rule, given a profit matrix - Determine optimum cutoff values from profit plots - Given a profit matrix, and model results, determine the model with the highest average profit SAS Statistical Business Analyst (A00-240) Certification Questions 01. Refer to the REG procedure output: 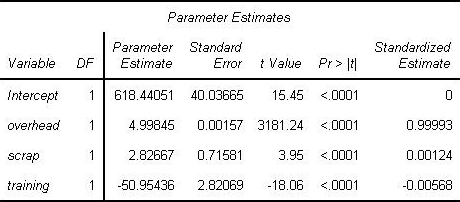 What is the most important predictor of the response variable? a) intercept b) overhead c) scrap d) raining 02. An analyst builds a logistic regression model which is 75% accurate at predicting the event of interest on the training data set. The analyst presents this accuracy rate to upper management as a measure of model assessment.What is the problem with presenting this measure of accuracy for model assessment? a) This accuracy rate is redundant with the misclassification rate. b) It is pessimistically biased since it is calculated from the data set used to train the model. c) This accuracy rate is redundant with the average squared error. d) It is optimistically biased since it is calculated from the data used to train the model. 03. The LOGISTIC procedure will be used to perform a regression analysis on a data set with a total of 10,000 records. A single input variable contains 30% missing records.How many total records will be used by PROC LOGISTIC for the regression analysis?Note:- You can use calculator for this question a) 7000 b) 9000 c) 7009 d) 9007 04. Which statement is an assumption of logistic regression? a) The sample size is greater than 100. b) The logit is a linear function of the predictors. c) The predictor variables are not correlated. d) The errors are normally distributed. 05. An analyst is screening for irrelevant variables by estimating strength of association between each input and the target variable. The analyst is using Spearman correlation and Hoeffding's D statistics in the CORR procedure.What would likely cause some inputs to have a large Hoeffding and a near zero Spearman statistic? a) nonmonotonic association between the variables b) linear association between the variables c) monotonic association between the variables d) no association between the variables 06. Refer to the exhibit: 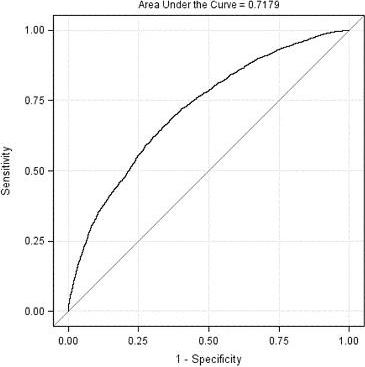 For the ROC curve shown, what is the meaning of the area under the curve? a) percent concordant plus percent tied b) percent concordant plus (.5 * percent tied) c) percent concordant plus (.5 * percent discordant) d) percent discordant plus percent tied 07. When selecting variables or effects using SELECTION=BACKWARD in the LOGISTIC procedure, the business analyst's model selection terminated at Step 3.What happened between Step 1 and Step 2? a) DF increased. b) AIC increased. c) Pr > Chisq increased. d) - 2 Log L increased. 08. A financial analyst wants to know whether assets in portfolio A are more risky (have higher variance) than those in portfolio B. The analyst computes the annual returns (or percent changes) for assets within each of the two groups and obtains the following output from the GLM procedure: 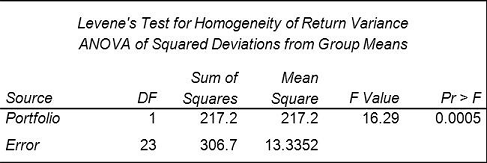 Which conclusion is supported by the output?
a) Assets in portfolio A are significantly more risky than assets in portfolio B. b) Assets in portfolio B are significantly more risky than assets in portfolio A. c) The portfolios differ significantly with respect to risk. d) The portfolios do not differ significantly with respect to risk. 09. An analyst has determined that there exists a significant effect due to region. The analyst needs to make pairwise comparisons of all eight regions and wants to control the experimentwise error rate.Which GLM procedure statement would provide the correct output? a) lsmeans Region / pdiff=all adjust=dunnett; b) lsmeans Region / pdiff=all adjust=tukey; c) lsmeans Region / pdiff=all adjust=lsd; d) lsmeans Region / pdiff=all adjust=none; 10. A linear model has the following characteristics:- a dependent variable (y)- one continuous predictor variables (x1) including a quadratic term (x12)- one categorical predictor variable (c1 with 3 levels)- one interaction term (c1 by x1)Which SAS program fits this model? a) proc glm data=SASUSER.MLR;class c1;model y = c1 x1 x1sq c1byx1 /solution;run; b) proc reg data=SASUSER.MLR;model y = c1 x1 x1sq c1byx1 /solution;run; c) proc glm data=SASUSER.MLR;class c1;model y = c1 x1 x1*x1 c1*x1 /solution;run; d) proc reg data=SASUSER.MLR;model y = c1 x1 x1*x1 c1*x1;run; Answers: Question: 01 - Answer: b Question: 02 - Answer: d Question: 03 - Answer: a Question: 04 - Answer: b Question: 05 - Answer: a Question: 06 - Answer: b Question: 07 - Answer: d Question: 08 - Answer: c Question: 09 - Answer: b Question: 10 - Answer: c How to Register for SAS Statistical Business Analyst Certification Exam? Visit site for Register SAS Statistical Business Analyst Certification Exam.
0 Comments
Leave a Reply. |
